This article is about basic 1D patterns recognition from 1D time domain signal, special case, voice patterns recognition. First, consider the parameters needed for human voice patterns recognition. Since human hearing frequency range is 20 to 20000 Hz, Nyquist says that sampling frequency should be doubled (44100 samples per second is selected).
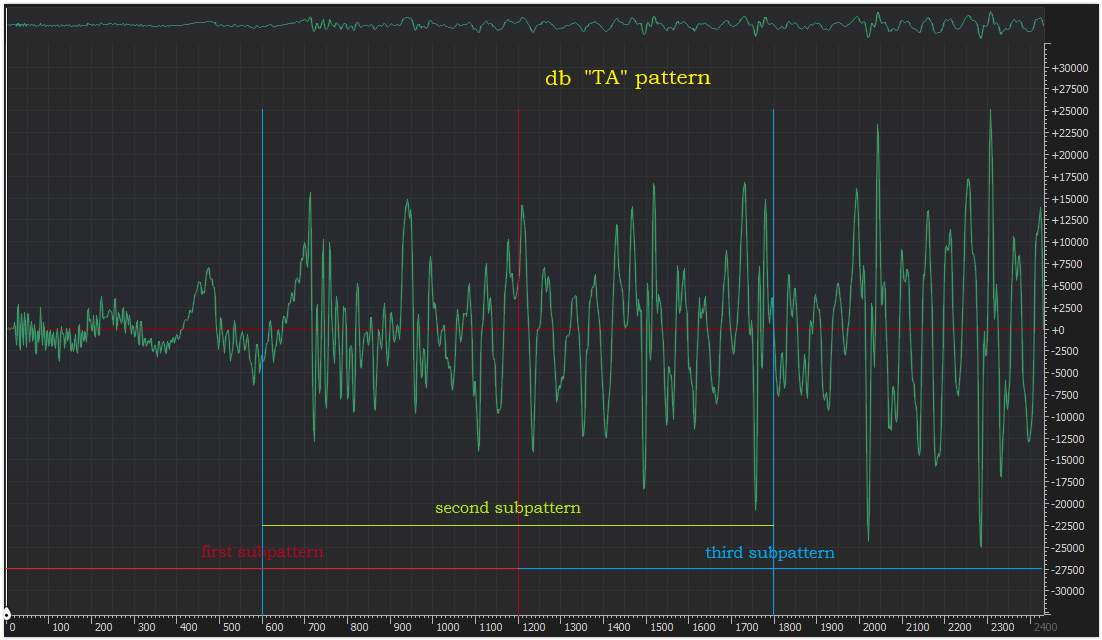
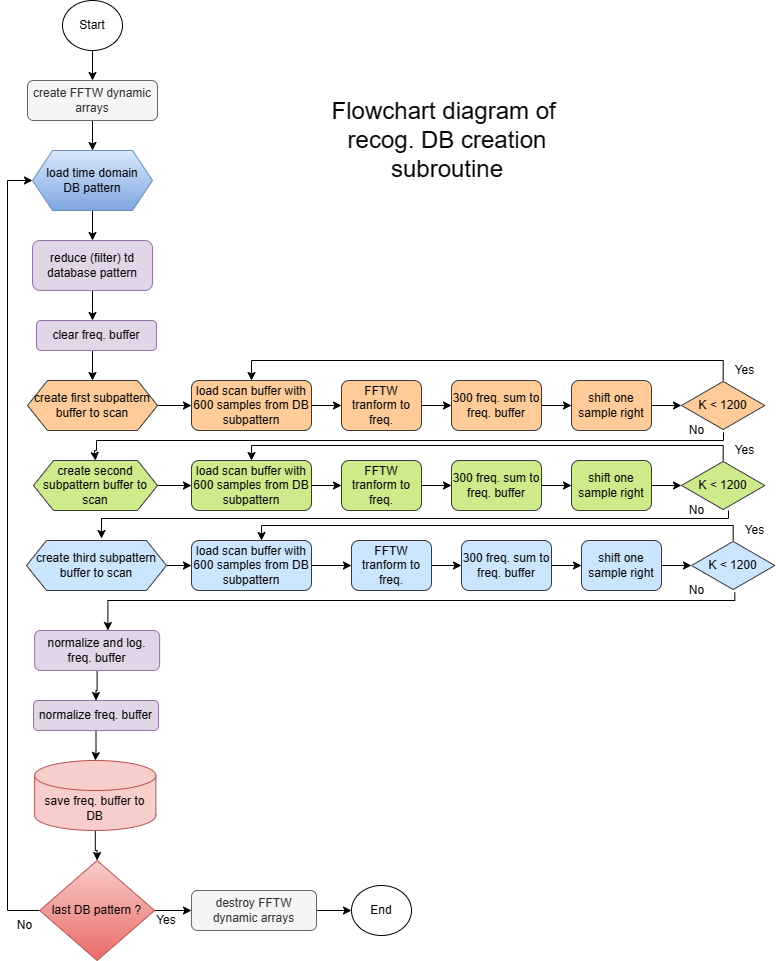
Experimentally, I found best voice pattern size (Croatian language) 2400 samples (1/44100*2400 = 54ms duration). This pattern size should be reduced (filtered) to half, because I do not need frequencies above 11025 Hz for recognition. So we have pattern size 1200 samples. Idea is to take buffer of size that should satisfy statistics (for ex. 600 samples), and scan pattern for frequencies. 600 samples means 300 frequencies (lowest = 36.75 Hz to highest = 11025 Hz in steps of 36.75 Hz). There are three reasons why I devided pattern in three subpatterns (image above), first, 300 freq. is statistically not enough, second, frequencies over 11025 Hz (300*36.75) I do not need for recognition, third, except for vocals (A, E, I, O, U) patterns are not the same in the begining, in the middle and on the end (for ex. TA, TE, TI, TO, TU). To scan each subpattern we must construct buffer for scan (size 3x600 samples) where we put subpattern in the way shown with image below. Each subpattern should has 1200 scan shifts, what is statistically enough. SCAN means, for each shift take 600 time domain samples, transform it to freq., add it to freq. buffer, shift one sample right, take next 600 samples, transform to freq., sum to freq. buffer... and do it 1200 times.
I can filter or reduce signal and patterns two times in size with FFT transform. In this case I get 1200 samples pattern size and 600 samples scan buffer size or 300 freq. With three subpatterns, I get 900 freq. for database freq. pattern size. This can significantly speed up the process of recognition.
buffer for scanning
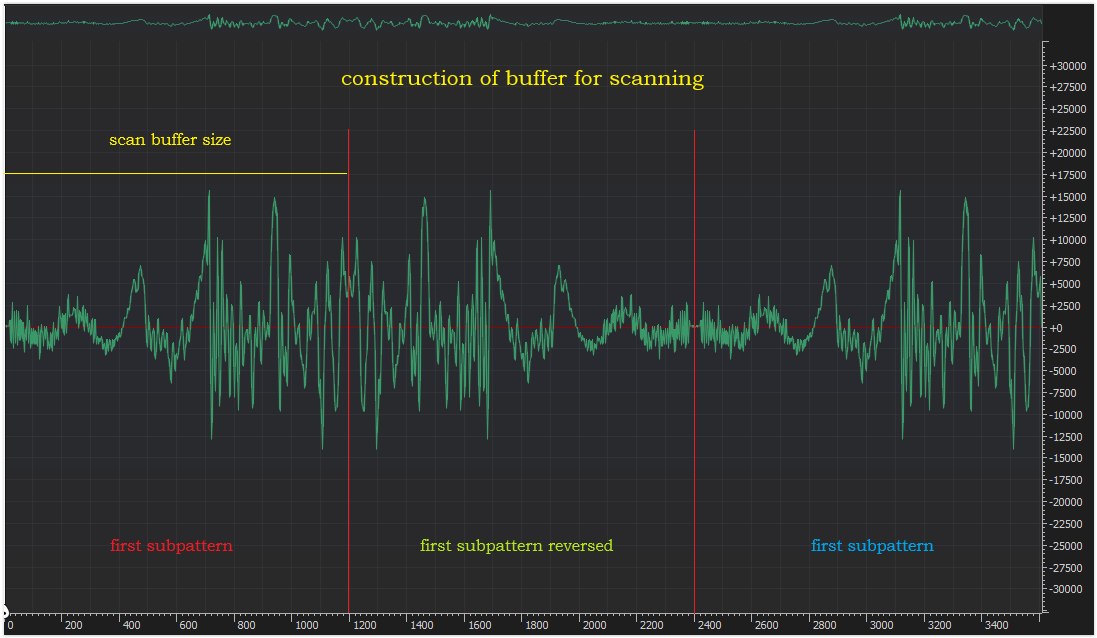
If you want to scan whole subpattern, you must span it three times. But if you span it in the ordinary way, there will be jumps between, what will very distord FFT. If you scan something with FFT from left to right or from right to left you will get the same result. So, to avoid jumps, I reversed middle subpattern.
Database creation starts with recording and saving time domain DB patterns (2400 samples each), 300 per each voice for each person. Important is to create patterns with different intensity levels, different intensity levels create different frequency patterns. The same is with different pitch frequencies. DB is created with the same number of patterns for each voice, it could be organized in the different ways, not necesery with the same number (tree structure, etc...).
Flowchart diagram for recognition DB creation process:
There is normalization before and after logarithm. During scanning process, for each subpattern, we sum frequencies in the freq. buffer. After scanning process we need to normalize the sum:
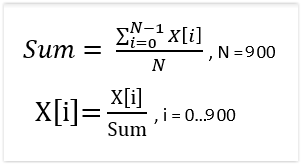
and after logarithm:
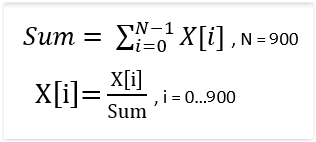
First normalization is preparation for logarithm to be taken on frequency buffer
X[i] = log(X[i] + 1),
and second normalization is preparation of frequency buffer for recognition proces. After this normalization sum of all (900) elements of freq. buffer is 1. It should be useful for probabilistic function in recognition process.
Now lets see example of frequency buffer stored in recognition DB:
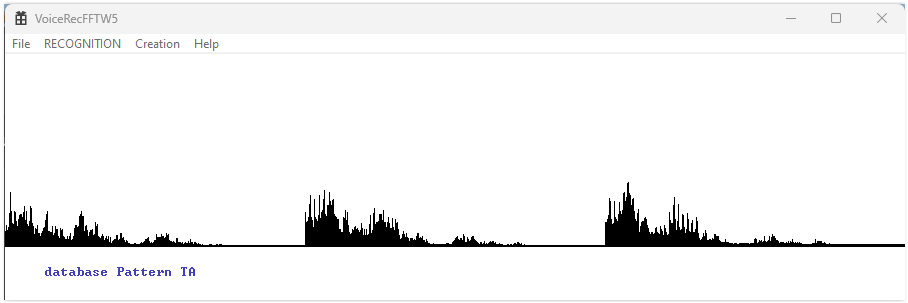
It consist three parts. First (300 freq.) is result of scanning first subpattern, second (300 freq.) of second subpattern and third (300 freq.) of third subpattern. And after logarithm and both normalization processes.
Recognition starts with signal loading. In this program, signal duration is limited to 544 mili seconds (24000 samples). Freq. patterns DB should be loaded before recognition (File --> LoadDataBase). Signal is then reduced (filtered) to half (12000 samples) with FFTW transform. After opening result file (store data for recognized patterns), program goes to recognition loop. Everything is done like in the DB creation except PNN() function in addition. PNN() (probabilistic neural network) calculates probability how much is actual pattern similar to DB patterns.
void PNN() {
int i, j;
double sum;
rez = -1; largest = 0;
for (i = 0; i < nrDbPatternsTotal; i++) {
sum = 0;
for (j = 0; j < 900; j++) {
sum += fabs(X[j] - R[i][j]);
}
sum = exp(-pow(sum, 8) / 0.0002);
if (sum > largest) {
largest = sum;
rez = i;
}
}
}

X is unknown freq. pattern from signal, R[i] is DB freq. pattern.
Outer for() loop selects DB freq. pattern, and inner for() loop sums differences between freq. from selected DB pattern and freq. of unknown pattern from signal. If two patterns are identical, sum of differences should be 0. In this case probability is 1.
ProcessResult() function detects which voice is pattern with position number (rez) from DB.
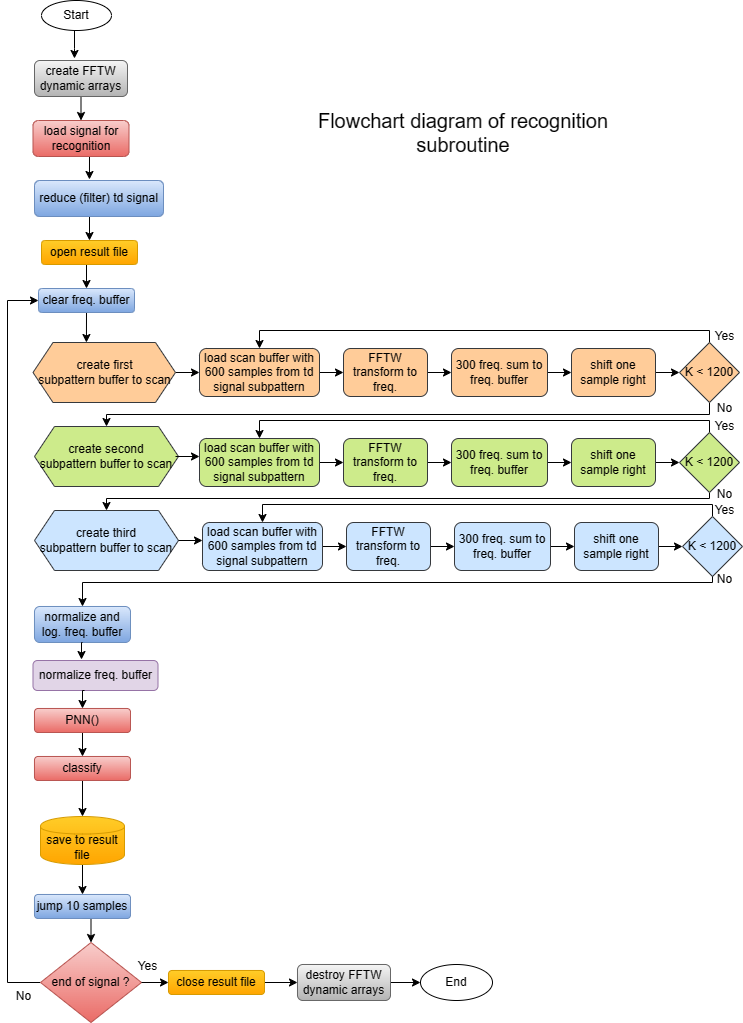
After signal is loaded (max 24000 samples), it is reduced (2x) (filtered) with FFT transform. Then program goes to the loop, where it creates freq. patterns which are then compared with DB freq. patterns for pattern classification. Recognition of patterns is performed in the jumps of 10 samples because of speed. Results of recognition in every step are saved to the result.txt file.
Example of signal file and result file:
DB element 58 with max probability (0.81968)
Probabilities for patterns in the ex. above are get with database of 7 voices (a, e, i, o, u, ta(1), da(2)) with 30 freq. patterns per voice, manualy cutted.
Manually created time domain DB patterns (300 or more), some of them could contain very similar freq. patterns. To avoid such cases, this subroutine orders patterns by mutual probability differences and then selects 30 freq. patterns for reduced database (R_DAT). This DB should be used for pattern recognition instead of 300 patterns database (DAT).
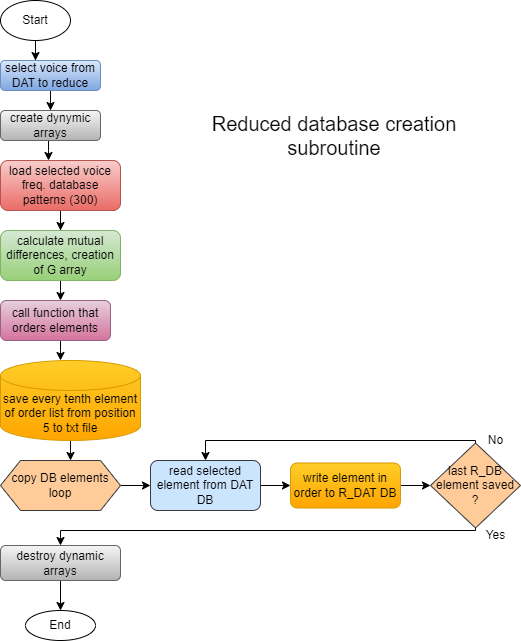
G array is array (300x300) of mutual probab. differences between DB elements. Distances() function orders elements according to mutual differences, starting from first element. Next selected element is one with smallest difference regarding first one, next selected element is one with smallest difference regarding all elements already selected.... This order is buffered in the variable put[]. After this process 30 elements for R_DAT are selected from put[], from position 5 in jumps of 10.
Program Codes:
Sources:
Dialogs: